Enhancing AI Accuracy For SQL Generations Using Retrieval-Augmented Generation
If you want to improve the accuracy of AI-powered SQL generations you usually do so by adding additional information and clauses to the prompt. These include table names that aren't oblivious or deducible from prompt itself or even better include the database schema, so AI can deduce all information needed itself (hopefully). These steps usually increase accuracy for well-structured unambiguous database schemas. And they allow the user to be less specific (and sloppy) when writing the prompt.
However these approaches often fall short when working with an actual database schema maimed by legacy usage patterns and naming. This results in multiple ways to understand and solve a given prompt instruction. To solve you can prime AI relevant suggestions for a particular prompt, retrieval-augmented generation (RAG). This enables us to add database schema semantics to AI and it is quite effective even on a small scale.
To train a data source using RAG, you simply click the actions button above the generation and then "Train AI". This will open a modal where you can see the prompt and generation to be stored. The prompt is vectorized and will automatically be run when generating queries later to increase accuracy.
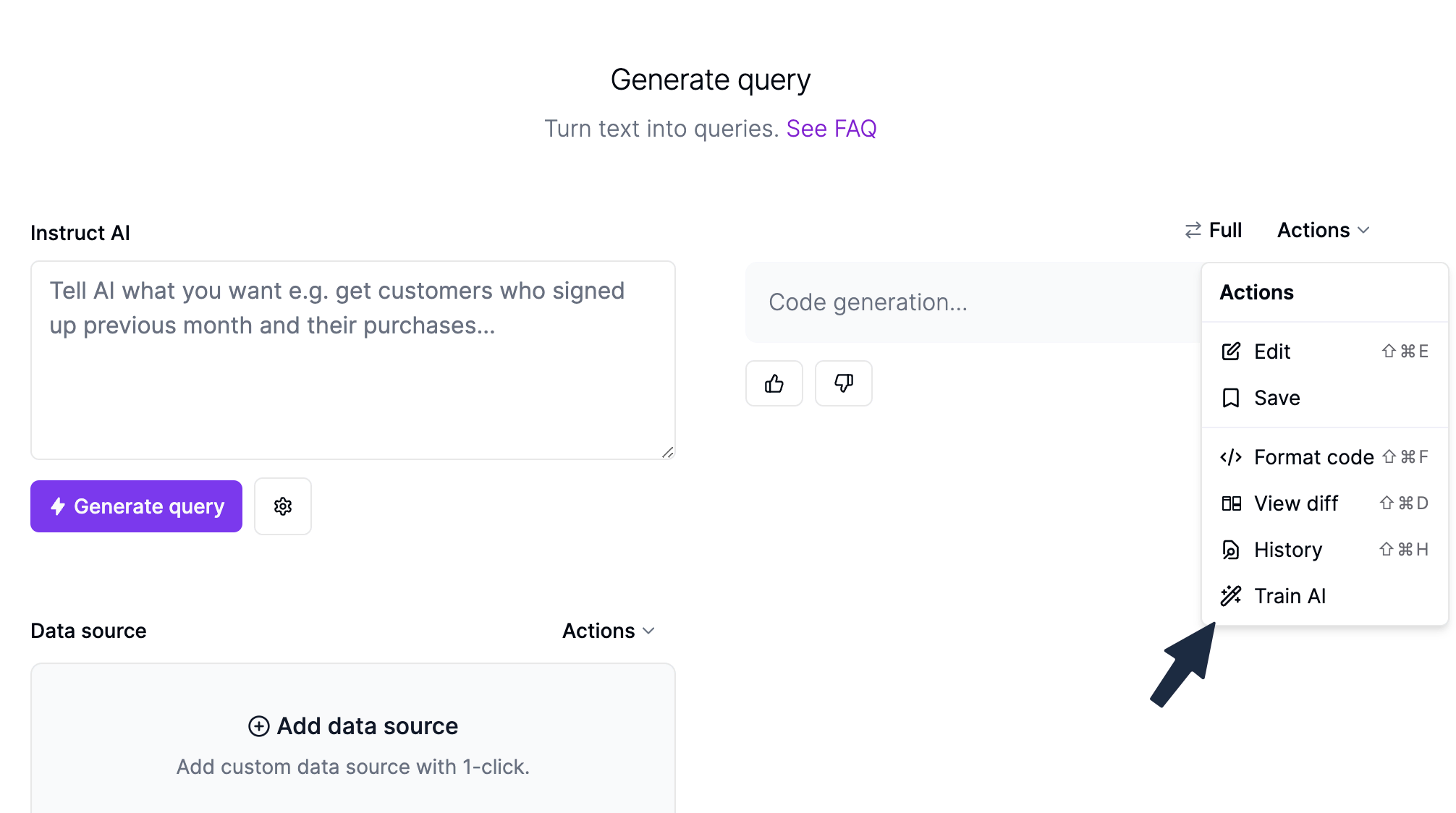
RAG training is implemented by storing the prompt and generation when the user "likes" the particular prompt-generation pair. The prompt-generation pair can manually be modified before liking.
SQLAI database example
For the database schema that this site runs on I want AI to be able to understand:
- table and column names must be wrapped in quotes since they are camel-cased and without PostgreSQL interpret them case-insensitively
- there are 2 subscription tables,
SubscriptionandLemonSubscription(naming due to payment provider) and AI should generally use the latter - when finding a subscription for a particular user it should use
lemonUserEmailfield onLemonSubscriptionrather than using a JOIN query with theUsertable
First to get AI to use the correct table lets run the prompt: Get subscriptions. It returns a faulty generation:
SELECT
*
FROM
Subscription;
To correct this and prepare it for RAG training I edit it to the desired response:
SELECT
*
FROM
"LemonSubscription";
On a side note, this could also be done by adding additional instructions to the prompt (i.e. "use LemonSubscription" and "wrap tables and columns in quotes") and then removing these additional instructions before submitting RAG training.
Now that we have a prompt-generation pair that points AI to a preferred table and notation, it can be saved. The prompt-generation pair is stored along with a vectorized version of the prompt, i.e. the embedding. Then whenever a user requests a generation in the future the system executes a vector search to find relevant context for prompt and includes it.
If we run the above generation again with the same prompt it will return the correct generation, i.e. using correct table name and notation. The prompt can be modified, e.g. Get subscriptions for user with id 123 or Get all cancelled subscriptions and AI will generate correct responses.
If we run the prompt Get subscriptions for user with john@doe.org it generates:
SELECT
*
FROM
"LemonSubscription"
JOIN
"User" ON "LemonSubscription"."userId" = "User"."id"
WHERE
"User"."email" = 'john@doe.org';
While it is correct and usable I want to use the lemonUserEmail field instead of a more expensive JOIN query. To achieve this I modify the query to fit the requirement:
SELECT
*
FROM
"LemonSubscription"
WHERE
"lemonUserEmail" = 'john@doe.org';
Now when I run a similar prompt Get subscriptions for user with jens@jensen.org AI generates the desired query:
SELECT
*
FROM
"LemonSubscription"
WHERE
"lemonUserEmail" = 'jens@jensen.org';
When I target other tables AI still uses the correct notation with the quotes. If for some reason I want to change an existing RAG training, e.g. Get subscriptions, I simply save a new prompt-generation pair with the same prompt. The latest added RAG training will be used.
I ran the generations using GPT-4 Turbo and while it is possible with GPT-3.5 Turbo it generally performs worse and interpret added RAG training to literally.